
Pengelompokan Email Phising Menggunakan Teknik ML DAN NLP

Metode pendeteksian email phishing menggunakan pembelajaran mesin terutama menggunakan email phishing yang ditandai dan email yang sah untuk melatih algoritma klasifikasi dengan algoritma pembelajaran mesin untuk mendapatkan model klasifikasi untuk klasifikasi email.
Pernyataan masalah:
Email palsu adalah hal biasa dalam budaya saat ini. Tujuan dari proyek ini adalah untuk membuat sistem yang menggunakan pembelajaran mesin dan teknik pemrosesan bahasa alami untuk menentukan apakah email dapat diandalkan.
Dalam task ini, kami membuat pengklasifikasi pembelajaran mesin yang dapat menghitung probabilitas phishing email. Masukan model terdiri dari fitur dan atribut email tertentu, dan keluaran yang diinginkan adalah "phishing" atau "bukan phishing".

Pengumpulan data:
Data untuk proyek ini dipinjam dari penulis makalah yang dikutip di bawah ini.
Data kepemilikan ini dapat dikumpulkan dengan menghubungkannya dengan penulis. Penulis secara manual mengumpulkan semua email phishing dan legal dan menyimpannya sebagai file teks (ekstensi.txt) dengan atau tanpa header email. Data dapat diperoleh dengan menghubungi penulis atau mengakses kutipan artikel di atas.
Deskripsi data:
Data awal yang diperoleh berupa file teks. Ada sekitar 500 file teks berlabel legal dan sekitar 4000 file teks berlabel phishing. File teks individual berisi kepala email yang digunakan dalam analisis injeksi
Dalam email, isi (teks konten) selalu didahului dengan baris header yang mengidentifikasi informasi perutean pesan, seperti pengirim, penerima, tanggal, dan subjek. Beberapa header, seperti FROM, TO, dan DATE header, diperlukan. Lainnya, seperti SUBJECT dan CC, adalah opsional tetapi sangat umum digunakan. Header lainnya termasuk mengirim dan menerima stempel waktu untuk semua agen transfer email yang mengirim dan menerima pesan. Dengan kata lain, setiap kali pesan diteruskan dari satu pengguna ke pengguna lain (yaitu, ketika pesan dikirim atau diteruskan), pesan tersebut dicap dengan tanggal/waktu oleh agen transfer surat (MTA). Meneruskan pesan email dari satu komputer ke komputer lain. Tanggal/cap waktu ini, seperti FROM, TO, SUBJECT, akan menjadi salah satu dari banyak header sebelum badan email.
Berikut adalah contoh file teks email:

Contoh file teks awal dari sebuah email
Persiapan data:
Analisis pertama menjalankan skrip Python yang membaca semua file teks, membaca konten file teks ke dalam kerangka data, dan melabeli setiap file teks sebagai 0 untuk Legit dan 1 untuk Phish. Kemudian saya memproses kerangka data dan menggunakan pustaka parser surat Python untuk mengekstrak tajuk file teks dan pendengaran pertama yang saya butuhkan untuk saat ini.

frame data awal:

Semua data yang diperlukan dari file teks dimasukkan ke dalam bingkai data untuk diproses lebih lanjut
Pilih untuk hanya menggunakan FROM, DATE, TO, SUBJECT, dan BODY dari semua header yang ada di email. Karena ini adalah header utama dan dapat ditemukan di semua email.
Kolom data:
- file_name: Ini menunjukkan nama file teks tempat data diekstraksi.
- From: Ini menunjukkan pengirim pesan, yang dapat dengan mudah dipalsukan dan paling tidak dapat diandalkan.
- Subject: Ini ditempatkan oleh pengirim sebagai topik untuk konten email.
- Date: Ini menunjukkan tanggal dan waktu ketika pesan email dibuat.
- To: Ini menunjukkan tujuan pesan, tetapi mungkin tidak menyertakan alamat penerima.
- body: Ini adalah isi sebenarnya dari email itu sendiri yang ditulis oleh pengirim.
- Phish: Ini menunjukkan apakah email itu phishing atau legal
Analisis data eksplorasi:
Langkah selanjutnya setelah data disiapkan untuk preprocessing perlu dibersihkan. Tidak ada kolom atau catatan yang hilang dan pengambilan dilakukan secara manual. Karena kita berurusan dengan data tekstual, kita harus menggunakan NLP untuk pembersihan dan analisis teks.
Prosedur pembersihan data:
- Hapus stopword
- Hapus tanda baca.
- Hapus karakter khusus
- Tokenisasi
- Kapitalisasi kata
Langkah-langkah di atas telah diterapkan pada subjek dan isi kolom kerangka data analisis awal.

chart Batang dari 20 kata teratas yang muncul di subjek Email Phishing
Chart batang di atas menunjukkan 20 kata tidak tepat teratas yang muncul di baris subjek email. Analisis korpus menemukan kata "akun", yang paling sering muncul (148 kali) dalam phishing. Ini sangat masuk akal, karena sebagian besar email phishing cenderung mendapatkan detail rekening bank pengguna dan rekening keuangan lain yang perlu ditargetkan. Kata yang paling sering digunakan berikutnya adalah "PayPal" (63 kali). Ini karena kami telah mengidentifikasi PayPal sebagai platform perangkat lunak untuk memproses bank dan pelanggan dengan kueri terkait transaksi.

Chart Batang dari 20 kata teratas yang muncul di subjek Email yang Sah
Juga, periksa kata-kata yang muncul di baris subjek email yang sah. Kata-kata seperti "video", "baru", "kartu", dan "panggilan" tampak acak di korpus mana pun. Saat ini, tidak mungkin untuk mendapatkan hubungan antara kata-kata seperti dalam email phishing, tetapi analisis lebih lanjut dapat mengungkapkan karakteristiknya. Tetapi memang benar bahwa kata "video" paling sering muncul dalam dokumen yang sah. Ini mungkin berkontribusi pada faktor bahwa data tidak seimbang, tetapi logikanya adalah bahwa kata "video" akan tampak jauh lebih besar. Banyak kali.
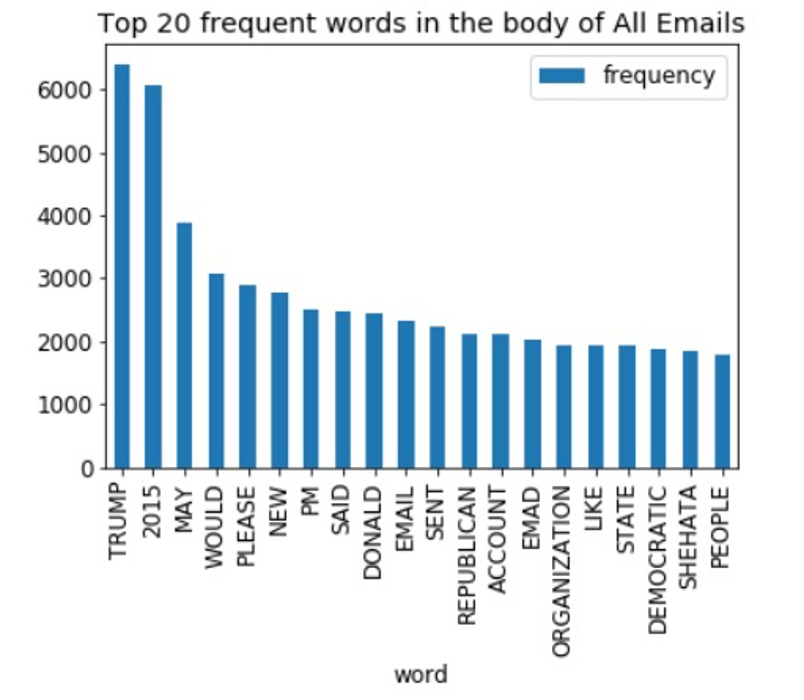
Chart Batang dari 20 kata teratas yang muncul di semua email
Setelah menganalisis subjek, kami juga menganalisis seluruh korpus, termasuk email phishing dan non-phishing. Anda dapat melihat bahwa kata-kata "Trump", "Donald", "Negara", "Republik", dan "Demokrat" adalah satu set dari ini. Kata-kata yang muncul di 20 besar korpus dapat dilihat atau ditandai sebagai kategori politik. Tampaknya juga menunjukkan "akun" pada saat 20 kata teratas dalam korpus yang juga termasuk dalam korpus phishing.

Class Distribution dari Email
Ini adalah distribusi data korpus sebagai legal dan phishing. Dalam kerangka data, "0" diberi label sebagai sah dan "1" diberi label sebagai phishing. Seperti yang ditunjukkan di awal, ada sekitar 4000 email yang sah dan 500 email phishing untuk melatih pengklasifikasi.
Rekayasa fitur:
Dari analisis, Anda dapat memikirkan pendekatan sederhana untuk menambahkan fitur yang dapat meningkatkan kinerja hasil. Fitur yang diekstraksi adalah:
- Frekuensi 5 Email Phishing Teratas
- Frekuensi 5 Kata Teratas di Email Resmi
- Frekuensi huruf besar
- Frekuensi tanda baca
- Frekuensi stopword
- Jam dan menit dari tanggal dan waktu

Data frame setelah rekayasa fitur
Gambar di atas menunjukkan semua fitur yang dapat diekstraksi dari preprocessing teks.- body_stop_frqq: Frekuensi stopwords di badan email tertentu
- sub_stop_frqq: Frekuensi stopwords di baris subjek email tertentu
- datehour: Waktu pengiriman email tertentu
- sub_uppercase_cnt: Frekuensi huruf besar di baris subjek email tertentu
- body_uppercase_cnt: Frekuensi huruf besar di badan email tertentu
- sub_punc_cnt: Frekuensi tanda baca pada subjek email tertentu
- body_punc_cnt: Frekuensi tanda baca di badan email tertentu
- body_top5_legit_cnt: Frekuensi 5 Kata Teratas dari Email Sah untuk Email Tertentu
- bosy_top5_phish_cnt: Frekuensi 5 kata teratas dalam email phishing untuk email tertentu
- dateminute: 1 menit dari waktu email tertentu terkirim
Analisis mengungkapkan bahwa sebagian besar email phishing memiliki nada sapaan yang tidak biasa. Saat membaca kata-kata yang tidak tepat digunakan. Kesalahan tata bahasa dan ejaan. Kontradiksi seperti baris subjek email huruf besar, ancaman atau urgensi, dan permintaan yang tidak biasa. Seperti disebutkan di atas, pengamatan ini didukung oleh analisis 20 kata teratas. Email phishing berisi kata-kata yang terkait dengan istilah perbankan seperti pembayaran dan akun. Berdasarkan intuisi ini, kami akan mengekstrak jumlah 5 kata teratas dalam email phishing dan memilih untuk menggunakannya sebagai fitur.
Pemodelan dan hasil:
Dari analisis tersebut, kita akan melanjutkan dengan metode menghitung vektorisasi dan menambahkan fitur seperti menghitung tanda baca dan menghitung huruf besar. Karena vektorisasi penghitungan menghasilkan data berdimensi tinggi (lebih dari 14.000 kata dalam korpus), kami merancang kemampuan untuk menggunakan frekuensi kata untuk menampung hanya 1000 kata teratas dan menggunakan frekuensi itu sebagai fitur.
Untuk subpengaturan data, gunakan pemisahan uji kereta Sklearn saat melatih model dan menguji model terlatih dalam pengujian. Juga, seperti yang disebutkan sebelumnya, saat menggunakan vektorisasi hitungan, tidak semua kata dalam data teks digunakan, tetapi saat menggunakan vektorisasi hitungan, stopwords, tanda baca, semua angka, kosong Menghapus string dan semua kata non-Inggris lainnya. Gunakan hanya 1000 kata teratas dan frekuensinya untuk klasifikasi. Hal ini dilakukan untuk menghindari kutukan dimensi dari algoritma ML.
Bagian ini menjelaskan algoritma ML yang digunakan untuk klasifikasi. Pendekatan naluriah pertama menggunakan algoritma multinomial naive Bayes. Ada ribuan perangkat lunak dan alat untuk menganalisis data numerik, tetapi hanya sedikit untuk teks. Multinomial Naive Bayes adalah salah satu klasifikasi pembelajaran terawasi yang paling populer digunakan dalam analisis data teks kategorikal.
Algoritma multinomial naive Bayes adalah metode pembelajaran probabilistik yang terutama digunakan dalam pemrosesan bahasa alami (NLP). Algoritma ini didasarkan pada teorema Bayes dan memprediksi tag teks seperti email dan artikel surat kabar. Ini menghitung probabilitas setiap tag dalam sampel tertentu dan memberikan tag yang paling mungkin sebagai output. Sebuah classifier naive Bayes adalah kumpulan dari banyak algoritma di mana semua algoritma berbagi satu prinsip umum, dan setiap fungsi yang diklasifikasikan independen dari yang lain. Ada tidaknya suatu fungsi tidak mempengaruhi ada tidaknya fungsi lainnya.
Naive Bayes adalah algoritma yang kuat yang digunakan untuk analisis data teks dan masalah multi-kelas. Untuk memahami bagaimana teorema Naive Bayes bekerja, penting untuk memahaminya terlebih dahulu, karena konsep teorema Bayes didasarkan pada yang terakhir. Teorema Bayes, dirumuskan oleh Thomas Bayes, menghitung probabilitas bahwa suatu peristiwa akan terjadi, berdasarkan pengetahuan sebelumnya tentang kondisi yang terkait dengan peristiwa tersebut. Ini didasarkan pada persamaan berikut:
P(A|B) = P(A)*P(B|A)/P(B) Sekarang kita menghitung probabilitas kelas A jika prediktor B sudah tersedia.
naive bayes multinomial dapat diterima sebagai pendekatan probabilistik untuk mengklasifikasikan dokumen ketika memeriksa frekuensi kata yang diberikan dalam dokumen teks. Istilah "kantong kata" adalah dokumen terpilih yang diproses dalam konteks naif Bayes, mengekspresikan dokumen itu sendiri sebagai tas dan memungkinkan setiap kosakata dalam tekstur muncul beberapa kali sebagai item di dalam tas. Banyak digunakan sebagai. Anda perlu mengetahui terlebih dahulu keberadaan kata-kata dalam sebuah teks yang diberikan agar dapat diklasifikasikan dengan baik. Pengklasifikasi ini bekerja dengan baik secara terpisah karena jumlah kata yang ditemukan dalam dokumen. Contoh area penggunaan untuk pendekatan ini adalah prediksi kategori yang cocok dalam dokumen, mengambil keuntungan dari penampilan kata-kata yang ditugaskan ke dokumen. Keluaran dari algoritma ini menghasilkan sebuah vektor yang terdiri dari nilai frekuensi bilangan bulat dalam kumpulan kata.
Sebelum melompat ke hasil, mari kita lihat bagaimana mengevaluasi model.
Indikator dan peringkat
Salah satu jenis penilai kinerja yang paling umum untuk pengklasifikasi teks adalah validasi bersama. Dengan metode ini, dataset pelatihan secara acak dibagi menjadi set data dengan panjang yang sama. Kemudian, untuk setiap set dengan panjang yang sama, pengklasifikasi teks dilatih di set yang tersisa untuk menguji prediksi. Ini membantu pengklasifikasi membuat prediksi untuk setiap set yang sesuai. Prediksi menghindari positif palsu atau positif palsu jika dibandingkan dengan data yang diberi tag manusia.
Hasil ini mengarah pada metrik berharga yang menunjukkan seberapa efektif pengklasifikasi.
Akurasi: Persentase teks yang diprediksi dengan tag yang benar.
Precision: Persentase teks yang didapat pengklasifikasi dari jumlah total contoh yang diprediksi untuk tag tertentu.
Ingat: Persentase jumlah total contoh yang diprediksi oleh pengklasifikasi untuk tag tertentu.
Skor F1: Rata-rata harmonik antara presisi dan daya ingat.
Fokus pada kecocokan dan ingatan model saat kita berurusan dengan kumpulan data yang tidak seimbang

Cuplikan kode di atas adalah hasil dari model dasar pendekatan multinomial naive-by. Hasil yang ditunjukkan pada tahap ini cukup untuk melanjutkan pendekatan ini, tetapi mari kita lihat hasil dari beberapa model yang lebih mendasar.
Model regresi logistik:
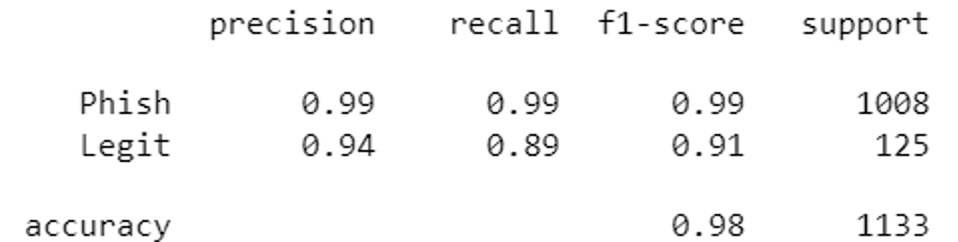
Logistic regression model Results
Model hutan acak:

Random Forest model Results

Feature importance from Random Forest

Bar chart of Feature Importance
Dari grafik batang di atas, Anda dapat melihat bahwa fitur yang diekstraksi berkontribusi signifikan terhadap klasifikasi email.
Bagaimana fitur penting dihitung di Random Forest? Klik disini untuk jawabannya.
Kesimpulan dan kata-kata terakhir
Melalui proses yang lengkap, Anda mungkin telah memperhatikan bahwa proyek ini lebih berpusat pada data daripada berpusat pada model dan berfokus pada pendekatan pemrosesan data untuk hasil yang lebih baik. Menurut teori Occam's Razor, pendekatan sederhana dan mudah diterapkan jika email yang meragukan tampaknya telah diterapkan dari sudut pandang saya.
Mengenai masalah proyek ini, saya ingin memasukkan penyesuaian parameter sebagai langkah selanjutnya. Pengetahuan domain dalam arti harfiah dan kiasan adalah manfaat tambahan (jika Anda melihat informasi pengguna seperti pengirim, rincian penerima, itu hilang untuk melindungi privasi Anda), dan yang paling penting. Apa yang terbatas data di area ini, memiliki data yang tidak proporsional tidak tidak melayani tujuan kita. Ini juga salah satu alasan mengapa klasifikasi email phishing berkontribusi lebih kecil daripada klasifikasi email spam.
Secara keseluruhan, model saat ini memberikan hasil yang cukup baik, tetapi pendekatan lain seperti jaringan saraf dan analisis sentimen pasti dapat meningkatkannya.
Sumber: https://medium.com/@sumbadsharan/phishing-email-classification-bff02f6b8df9